




Tối ưu file robots.txt cho blogspot
Tối ưu file robots.txt cho blogspot
Tối ưu file robots.txt cho blogspot - Tối ưu file robots.txt cho blogger
Disallow:
User-agent: *
Allow: /
Disallow: /search
User-agent: Cho những robot tìm kiếm từ Google, Yahoo và MSN nên sử dụng hướng dẫn này của bạn để tìm kiếm trang web.
Allow: / Dòng code này cho phép công cụ tìm kiếm index đọc tất cả nội dung
Disallow: /search: Dòng code này báo cho công cụ tìm kiếm biết nó không nên “lục lọi” ở những file này
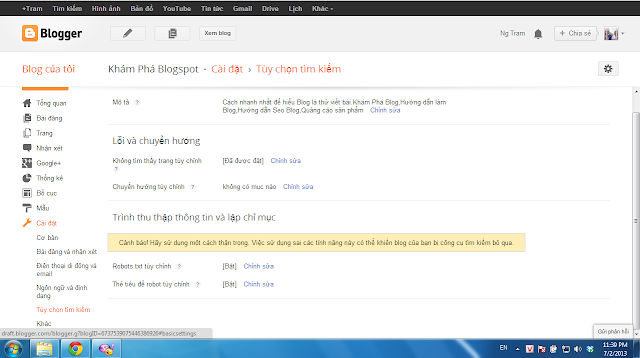
Hinh 1
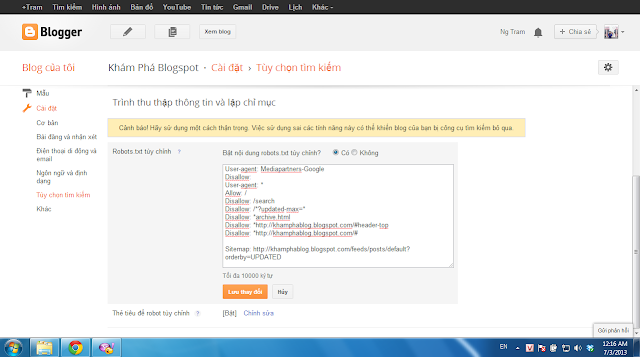
Hinh 2
Code chuẩn robots.txt cho blogspot
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Allow: /
Disallow: /search
Disallow: /*?updated-max=*
Disallow: *archive.html
Sitemap: http://blogcuaban/feeds/posts/default?orderby=UPDATED
Còn tùy vào blog bạn chặn trang hoặc thưc mục các bạn tùy chỉnh nhé.
Gợi ý cho các bạn.
Chặn 1 thư mục và mọi thứ nằm trong nó
Disallow: /search
Chặn 1 trang lưu trữ
Disallow: *archive.html
Cũng không khó lắm phải không. Quan trọng là biết dùng đúng cách sao cho phù hợp.
Nếu chưa hiểu hoặc gặp khó khăn khi tạo các bạn cứ comment bên dưới để mình trả lời.
Tìm hiểu file robots.txt là gì?
File robots.txt là một dạng file rất đơn giản có thể được tảo bởi công cụ Notepad. Để các bộ máy tìm kiếm quản lý index nội dung của website bạn.Cấu trúc của robots.txt của blogspot.
User-agent: Mediapartners-GoogleDisallow:
User-agent: *
Allow: /
Disallow: /search
User-agent: Cho những robot tìm kiếm từ Google, Yahoo và MSN nên sử dụng hướng dẫn này của bạn để tìm kiếm trang web.
Allow: / Dòng code này cho phép công cụ tìm kiếm index đọc tất cả nội dung
Disallow: /search: Dòng code này báo cho công cụ tìm kiếm biết nó không nên “lục lọi” ở những file này
Hướng dẫn tạo và sử dụng file robots.txt cho blogspot
- Bước 1: Đăng nhập blogspot
- Bước 2: Kéo chuột xuống dưới bên tay trái vào "Cài đặt" [Hình 1]
- Bước 3: Chọn "Tùy chọn tìm kiếm" trong menu cài đặt
- Bước 4: Chọn "Trình thu thập thông tin và lập chỉ mục" bên tay phải của Tùy chọn tìm kiếm [Hình 2]
- Bước 5: Chọn "Robots.txt tùy chỉnh" >> "Bật nội dung robots.txt tùy chỉnh"
- Bước 6: Copy đoạn code chuẩn này vào khung nhập text và sau đó nhấp "lưu lại"
Hinh 1

Hinh 2

Code chuẩn robots.txt cho blogspot
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Allow: /
Disallow: /search
Disallow: /*?updated-max=*
Disallow: *archive.html
Sitemap: http://blogcuaban/feeds/posts/default?orderby=UPDATED
Còn tùy vào blog bạn chặn trang hoặc thưc mục các bạn tùy chỉnh nhé.
Gợi ý cho các bạn.
Chặn 1 thư mục và mọi thứ nằm trong nó
Disallow: /search
Chặn 1 trang lưu trữ
Disallow: *archive.html
Cũng không khó lắm phải không. Quan trọng là biết dùng đúng cách sao cho phù hợp.
Nếu chưa hiểu hoặc gặp khó khăn khi tạo các bạn cứ comment bên dưới để mình trả lời.



